Ивану 21 год, в Promobot он занимается разработкам в области машинного обучения. Ваня вместе с командой создал нейросеть, которая определяет вероятность раковой опухоли. Работа вошла в 1% лучших на соревновании Google.
С чего всё началось

Я начал заниматься машинным обучением ещё 3 года назад, но серьёзно изучать глубокие нейронные сети стал не так давно — меньше года назад. Сейчас я работаю над обработкой естественного языка для сервисных роботов Promobot. «Естественный язык» — это речь человека, которую робот, стоя, например, в банке — должен обработать и оказать правильную услугу.
Полгода назад я решил, что глубокие нейронные сети мне интересы — и начал изучать всё, что было в доступе.
Буквально за два месяца я прошёл четыре больших курса по машинному обучению, прочёл больше 50 научных статей. Все курсы бесплатные, только за один я заплатил 3 000 ₽ (вообще-то это цена одного месяца курса, но я успел пройти всю программу за этот месяц).
— Специализация от Эндрю Ына по глубокому обучению из 5 курсов (платно)
— курс от Стэнфорда по компьютерному зрению (бесплатно)
— Курс от Стэнфорда по обработке естественного языка (бесплатно)
— Fast AI (бесплатно)
Все курсы на английском
Конечно, это не здоровый темп. По-хорошему такой объём информации проходят гораздо дольше, но я занимался по 12-14 часов в день под кофе, зелёным чаем и всем, что только мог найти.
У любого образования должен быть выхлоп — результат, практика, решение, п̶о̶с̶т̶ ̶в̶ ̶и̶н̶с̶т̶а̶г̶р̶а̶м̶е. Я решил участвовать в соревновании на гугловской платформе Kaggle.
Что за соревнование
Kaggle — это платформа международных соревнований по машинному обучению. В каждом соревновании участвуют тысячи исследователей — вместе с нами соревновались 1157 команд из США, Германии, Китая, Кореи — со всего мира.
Платформа предоставляет данные. В нашем случае это снимки лимфоузлов: 220 тысяч снимков для тренировки, и 57 тысяч — для тестирования модели. Это снимки реальных пациентов, переданные для исследования (снимки анонимные — личные данные пациентов не разглашаются). Такой набор данных называют dataset, и они бывают разные: могут состоять из снимков, видеофрагментов, текстов, или записей речи людей, как в моём случае в Promobot. (Объём тоже может быть разным: я работал и с 1 тысячей данных, и с 10 миллионами).
Задача простая: определить по снимку — есть у пациента рак или нет.
Как мы это сделали?
С помощью нейросети.
Как это работает
Чтобы научить чему-то нейросеть, нужно найти закономерность.
Например, работая с речью людей, нейросеть должна найти связь между репликами людей и услугой — допустим, окном в МФЦ. Представьте: человек подходит к роботу Promobot и говорит: «Мне нужно оформить загран». Не «заграничный паспорт», а именно «загран». В системе госуслуг нет «заграна», но нейросеть должна понять, в какое окно отправить клиента.
В случае изображений: чем отличаются снимки, на которых есть рак, от тех, на которых его нет?
Для этого изображение нужно перевести в данные. Здесь начинается интересное.
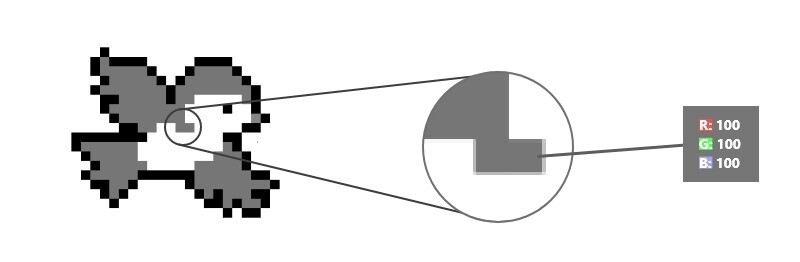
1. Любое изображение состоит из пикселей
Пиксели делятся на три канала: R (red), G (green) и B (blue). Если вы хоть раз в жизни открывали фотошоп или любую подобную программу, вы должны это знать.
У каждого канала есть значение. Это число — просто количество красного/зеленого/синего в каждом конкретном пикселе.
Представим, что у нас черно-белое изображение — в этом случае каждый пиксель кодируется одним числом.
2. Берём небольшую часть изображения
Например, 5 на 5 пикселей. У каждого есть своё значение, помните?

«Обычная» нейросеть перемножает значения всех пикселей со всеми значениями нейронов из следующего слоя. Этот процесс повторяется для всех слоев. Звучит сложно. К тому же это долго, объёмно и недостаточно точно.
Мы используем свёрточные нейронные сети, главная идея которых — свёртка. Суть в том, что каждый фрагмент изображения отдельно умножается на какое-то число (матрицу свёртки). Результат суммируется и записывается в итоговое изображение — в том же самом месте, в том же фрагменте.
3. Накладываем на изображение матрицу
Например, 2 на 2 пикселя. Каждое значение из этого квадратика умножается на какое-то число (например, на 3), а потом суммируется.
Затем смещаем его — и считаем значения уже в другом. Затем снова смещаем — и так до тех пор, пока не обработаем всё.
И эта операция проходит для каждого канала — красного, зеленого и синего (ведь у каждого пикселя есть три значения).
 4. Получается небольшой кубик
4. Получается небольшой кубик
Этот кубик — то же самое изображение, но как бы более концентрированное. Изображение было большим и непонятным, а мы сделали его меньше и точнее.

А теперь представьте количество значений и расчётов такого изображения:
 А теперь представьте, что оно выглядит вот так:
А теперь представьте, что оно выглядит вот так:
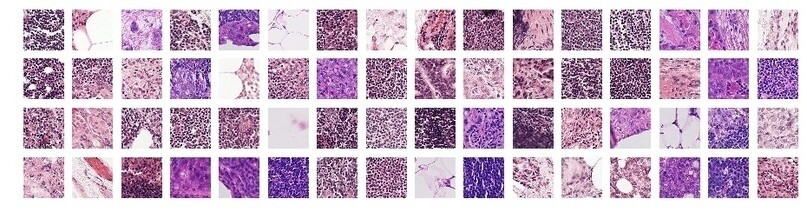
А теперь представьте, что таких изображений — 57 000.
5. В конце нейросеть выдаёт одно значение
Которое говорит: есть рак или нет. Побеждает тот, чья нейросеть была точнее других.
Я работал в команде: двое из Германии, один индиец из Англии и я, Ваня из России, из компании Promobot. Мы нашлись прямо на форуме соревнования. Я был самым младшим в команде: мне 21, индийцу — около 25-ти (и у него есть PhD в квантовой информатике), обоим немцам — в районе 35-ти.
Результат
В соревновании участвовали 1157 команд. Мы вошли в 1% лучших.
Сложно сказать, чем именно мы были лучше других. Команды публикуют свои решения добровольно, и обычно этим занимаются только топовые команды (если у тебя плохое решение, то и нет смысла его публиковать — логика такая).
Большую роль играет везение (да-да, везение в разработке нейронных сетей). Дело в том, что тренировка нейронной сети — это недетерминированный процесс. То есть каждый раз, когда ты его запускаешь, у тебя получается новая сеть. Тебе может повезти, а может не повезти — сеть сработает чуть лучших или чуть хуже — такое бывает.
Я знаю, что мы собрали чуть ли не лучшее решение, которое вообще можно было тогда собрать. Мы использовали почти все фишки, которые знали и которые именно сейчас на острие машинного обучения.

P.S. Затем мы взяли идеи, которые использовали на соревновании, собрали всё в одну статью и подали её на международную конференцию по машинному зрению CVPR — одну из самых топовых в мире.
Работа прошла проверку экспертов, и мы (а точнее всего один участник команды) представили её в Калифорнии. Лучшей работа не стала.





